Personal | July ~ August 2025
Shipping a full-stack trading advisor
OVERVIEW
Automating a data-driven trading operations strategy
My family took a class on Turtle Trading, and I wanted to automate the process of trading and minimize the impact of human emotions. From finding the right stocks with strong momentum to risk management, I wanted to build a Jarvis-like assistant that would help me make data-driven decisions.
PLANNING
Everything to be a formula of repeated tasks
When trading stocks, there are mainly two components of actions – buying and selling. The goal is to minimize the loss and maximize the profit.
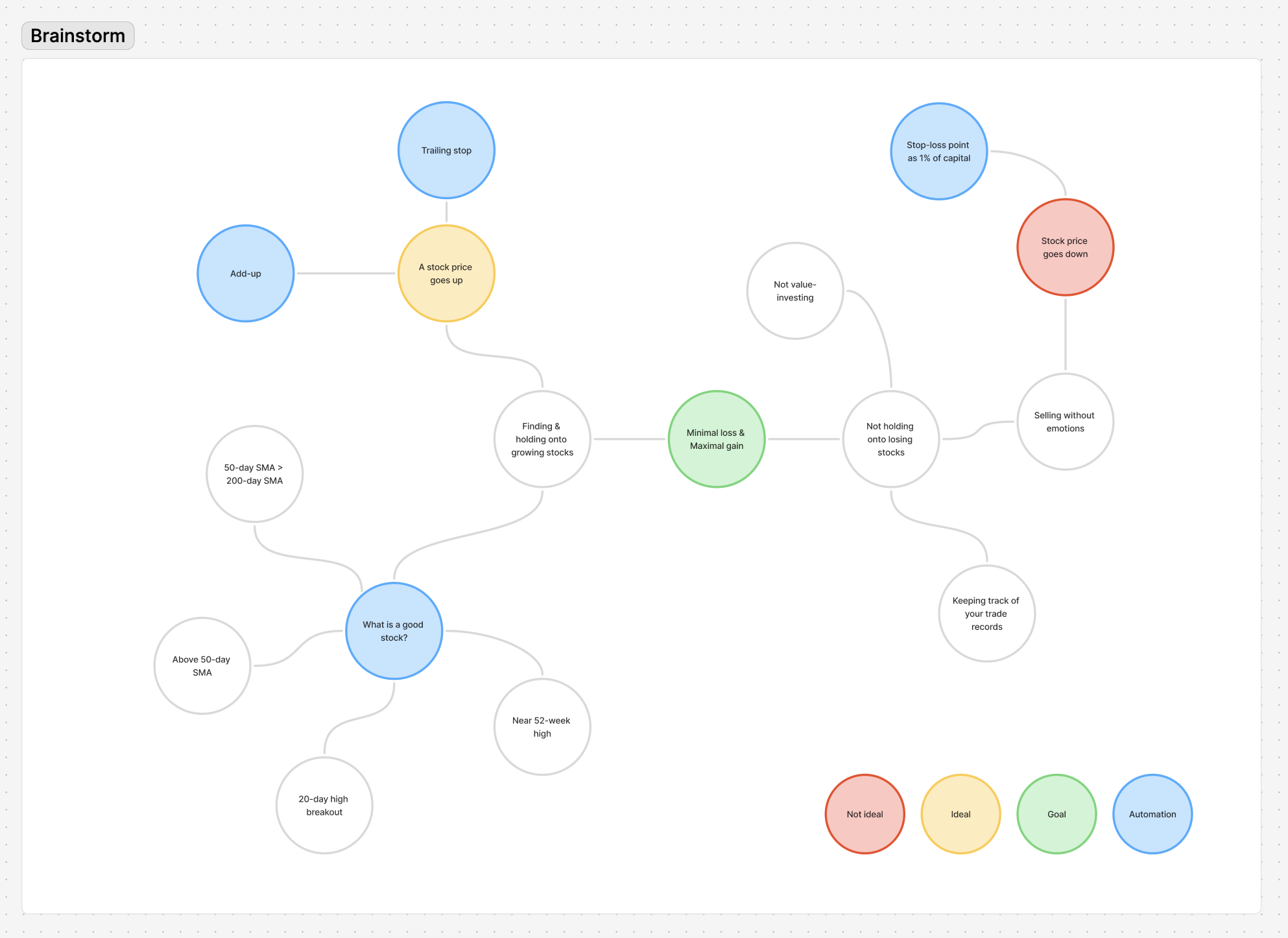
Core components of a systematic trading advisory platform
Pre-entry
- Market scanner: Monitors multiple markets for trading opportunities. Finds and suggests stocks that satisfy the designed criteria.
Entry
- Entry point: Checking the stock's momentum, volatility, and market strength indicators.
- Position size: Calculated based on user capital, risk tolerance, and stock's volatility.
Post-entry
- Stop-loss calculation: Depending on the risk tolerance, the stop-loss is calculated as a percentage below of the entry price.
- Risk Management: Automated position sizing based on account size and volatility, plus dynamic stop-loss adjustment.
- Add-up: When a stock price goes up to a certain point, we buy more shares, joining the trend.
- Trailing stop: When adding up, we need to calculate the trailing stop to protect the profit while not exiting too early.
IMPLEMENTATION
Technical architecture
The platform is built with a modular architecture that prioritizes reliability, performance, and maintainability:
Backend Infrastructure
- FastAPI with Uvicorn ASGI server
- JWT Authentication, password hashing
- Configurable CORS protection
Frontend Application
- React.js for hooks and functional components
- Tailwind CSS for styling
- Firebase hosting configuration
- Node.js for npm and package management
Database
- SQLite for development, PostgreSQL for production
- SQLAlchemy ORM with Alembic migrations
Data Pipeline
- Yahoo Finance API for historical data
- FinnHub API for real-time quotes
- API response-driven frontend state synchronization
MODIFICATIONS
From manual bottlenecks to automated flow
Beginning the flow on demand, it took more than 5 minutes to get the daily analysis done for ~600 stocks. This was a problem because the execution regularly exceeded the system's time limit. This would lead to timeout errors.
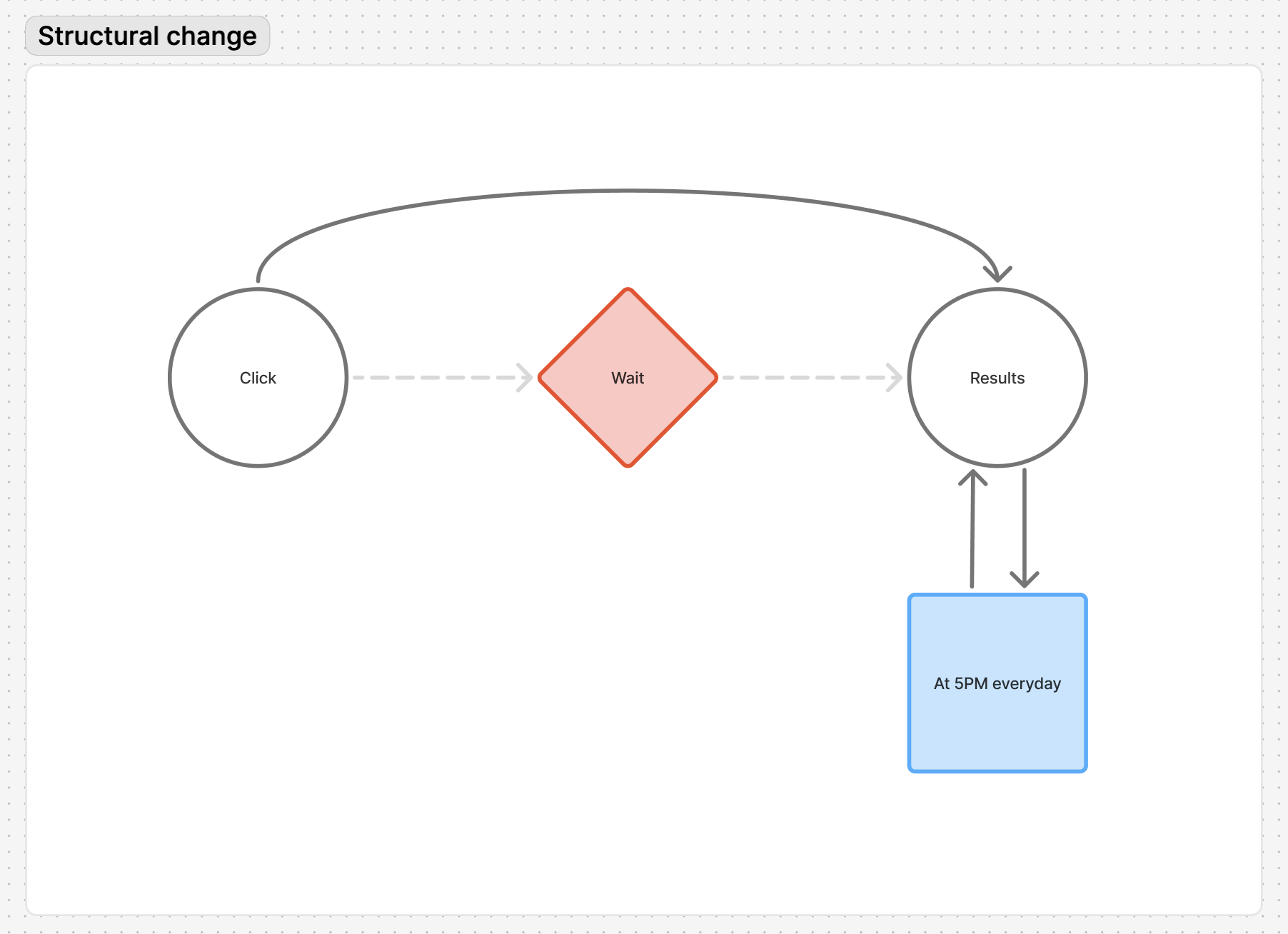
Previously...
- Users had to trigger manually each time
- Processing 600+ stocks took time
- No automation or progress visibility
- Click -> wait -> results, with unpredictable timing
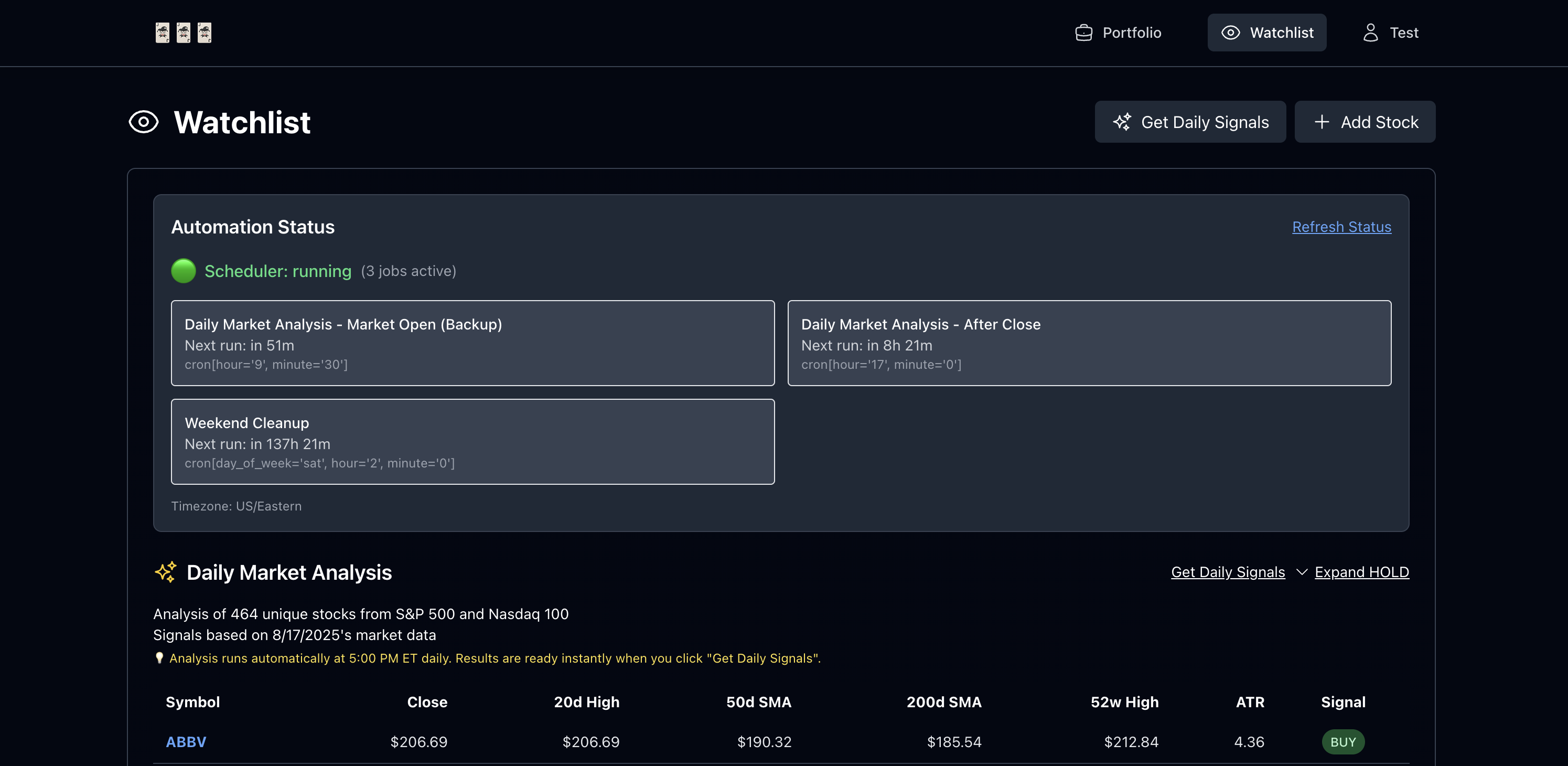
But now...
- Analysis now runs automatically at 5:00 PM ET
- Results are cached in DB and instantly available
- Fallback established for unexpected errors
- Users see system status, next run times, and health
- Click -> results, consistent and transparent
Key benefits
- Performance: 0.1s response vs several minutes on demand
- Transparency: clear status and scheduling info
- Efficiency: no redundant runs
- Robustness: backup scheduling and error handling
RESULTS
Log In
Daily Market Analysis
Adding Stock
Add Up
Selling
Trade History
TAKEAWAYS
Efficient code
With copilot tools like Cursor, it's insane how fast I can build. However, that makes it more important to have the technical understanding to make informed decisions.
Information architecture
For a full-stack perspective, it's crucial to establish a sustainable architecture that can scale – especially regarding data flow and how to optimize it.
Version control
Many times, updated codes ended up with a compile error. It was important to keep track of every changes, and go through the trial and error process to fix it.